First of all, thanks Dr. Charles Russell Severance
Why I write this summary?
- gained certificate from last winter vacation(2019)
- need to apply this knowledge for data access

Chapter 11 Regular expressions
Regular expressions (regex) are almost their own little programming language for searching and parsing strings.
_For more detail on regex, see: wiki, python docs._
Cheat Sheet
| symbol | function |
|---|---|
| ^ | Matches the beginning of a line |
| $ | Matches the end of the line |
| . | Matches any character (a wildcard) |
| \s | Matches whitespace |
| \S | Matches any non-whitespace character |
| ? | Repeats a character zero or one time |
| ?? | Repeats a character zero of one time (non-greedy) |
| * | Repeats a character zero or more times |
| *? | Repeats a character zero or more times (non-greedy) |
| + | Repeats a character one or more times |
| +? | Repeats a character one or more times (non-greedy) |
| [aeiou] | Matches a single character in the listed set |
| [\^XYZ] | Matches a single character not in the listed set |
| [a-z0-9] | The set of characters can include a range |
| ( | Indicates where string extraction is to start |
| ) | Indicates where string extraction is to end |
| \b | Matches the empty string only at the start of end of word |
| \B | Matches the empty string not at the start or end of a word |
| \d | Matches any decimal digit (equivalent to [0-9]) |
| \D | Matches any non-digit character (equivalent to [\^0-9]) |
_Note:_
- symbol with repeat function applies to the immediately preceding character(s)
- greedy matching: the repeat characters ( * and + ) push outward in both directions to match the largest possible string
- non-greedy doesn’t mean that the regex will try to find the shortest substring by varying the start index. It just means that if there’s a substring which starts at index 0 and matches the regex, the engine will stop as soon as possible
- escape character: by prefixing with a backslash. i.e. \$ indicate dollar sign instead of the wildcard.
Examples
Case 1
1 | # Search for lines that start with From and have an at sign |
The search string ^From:.+@ will successfully match lines that start with “From:“, followed by one or more characters (.+), followed by an at-sign. So this will match the following line:
From: stephen.marquard@uct.ac.za
Case 2
1 | import re |
Since we prefix the dollar sign with a backslash, it actually matches the dollar sign in the input string instead of matching the “end of line”, and the rest of the regular expression matches one or more digits or the period character.
Note: inside square brackets, characters are not “special”. So, when we say [0-9.], it really means digits or a period . Outside of square brackets, a period is the “wildcard” character and matches any character. Inside square brackets, the period is a period.
Chapter 12 Networked Programs
12.1 Hypertext Transfer Protocol - HTTP
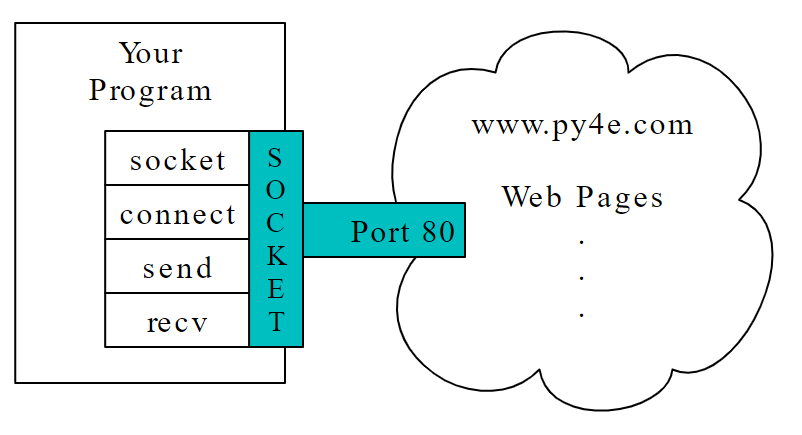
Socket/TCP Connections
A network connection between two applications where the applications can send and receive data in either direction.TCP Port Numbers
A number that generally indicates which application you are contacting when you make a socket connection to a server. As an example, web traffic usually uses port 80 while email traffic uses port 25.Protocol
A protocol is a set of precise rules that all parties follow so we can predict each other’s behavior. In a sense the two applications at either end of the socket are doing a dance and making sure not to step on each other’s toes.
HyperText Transfer Protocol, a long and complex 176-page document with a lot of detail. If you find it interesting, feel free to read it all. But if you take a look around page 36 of RFC2616 you will find the syntax for the GET request.
12.2 The world’s simplest web browser
1 | # Code: http://www.py4e.com/code3/socket1.py |
Output:
HTTP/1.1 200 OK
Date: Fri, 14 Feb 2020 23:05:30 GMT
Server: Apache/2.4.18 (Ubuntu)
Last-Modified: Sat, 13 May 2017 11:22:22 GMT
ETag: “a7-54f6609245537”
Accept-Ranges: bytes
Content-Length: 167
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: text/plainBut soft what light through yonder window breaks
It is the east and Juliet is the sun
Arise fair sun and kill the envious moon
Who is already sick and pale with grief
12.3 Retrieving an image over HTTP
1 | # Code: http://www.py4e.com/code3/urljpeg.py |
Output:
1408 1408
5120 6528
5120 11648
…… ……
5120 221568
3920 230608
Header length 394
HTTP/1.1 200 OK
Date: Fri, 14 Feb 2020 23:21:44 GMT
Server: Apache/2.4.18 (Ubuntu)
Last-Modified: Mon, 15 May 2017 12:27:40 GMT
ETag: “38342-54f8f2e5b6277”
Accept-Ranges: bytes
Content-Length: 230210
Vary: Accept-Encoding
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: image/jpeg
There is a buffer between the server making send() requests and our application making recv() requests. When we run the program with the delay in place, at some point the server might fill up the buffer in the socket and be forced to pause until our program starts to empty the buffer.
The pausing of either the sending application or the receiving application is called “flow control“.
12.4 Retrieving web pages with urllib
urllib: does all the socket work for us and makes web pages look like a file.
Using urllib, you can treat a web page much like a file. You simply indicate which web page you would like to retrieve and urllib handles all of the HTTP protocol and header details.
The equivalent code to read the romeo.txt file from the web using urllib is as follows:
1 | # Code: http://www.py4e.com/code3/urllib1.py |
When the program runs, we only see the output of the contents of the file. The headers are still sent, but the urllib code consumes the headers and only returns the data to us.
Output:
But soft what light through yonder window breaks
It is the east and Juliet is the sun
Arise fair sun and kill the envious moon
Who is already sick and pale with grief
Example
retrieve the data for romeo.txt and compute the frequency of each word in the file
1 | # Code: http://www.py4e.com/code3/urlwords.py |
Output:
{‘But’: 1, ‘soft’: 1, ‘what’: 1, ‘light’: 1, ‘through’: 1, ‘yonder’: 1, ‘window’: 1, ‘breaks’: 1, ‘It’: 1, ‘is’: 3, ‘the’: 3, ‘east’: 1, ‘and’: 3, ‘Juliet’: 1, ‘sun’: 2, ‘Arise’: 1, ‘fair’: 1, ‘kill’: 1, ‘envious’: 1, ‘moon’: 1, ‘Who’: 1, ‘already’: 1, ‘sick’: 1, ‘pale’: 1, ‘with’: 1, ‘grief’: 1}
12.5 Reading binary files using urllib
1 | #Code: http://www.py4e.com/code3/curl2.py |
read only 100,000 characters at a time and then write those characters to the cover.jpg file before retrieving the next 100,000 characters of data from the web.
12.6 Parsing HTML and scraping the web
One of the common uses of the
urllibcapability in Python is to scrape the web. Web scraping is when we write a program that pretends to be a web browser and retrieves pages, then examines the data in those pages looking for patterns.As an example, a search engine such as Google will look at the source of one web page and extract the links to other pages and retrieve those pages, extracting links, and so on. Using this technique, Google spiders its way through nearly all of the pages on the web.
Google also uses the frequency of links from pages it finds to a particular page as one measure of how “important” a page is and how high the page should appear in its search results.
12.7 Parsing HTML using regular expressions
For the simple webpage:
1 | <h1>The First Page</h1> |
We can construct a well-formed regular expression to match and extract the link values from the above text as follows:
href=”(http://.+?)”
1 | # Code: http://www.py4e.com/code3/urlregex.py |
Output:
Enter - https://yihang-li.github.io/
http://yihang-li.github.io/
http://Yihang-Li.github.io/2020/02/14/Summary-of-UPtoAWD-Coursera/
http://Yihang-Li.github.io/2020/02/10/Summary-for-visualization-of-geospatial-data/
http://Yihang-Li.github.io/2020/02/08/Notes-of-Gaussian-Processes-for-Machine-Learning/
http://Yihang-Li.github.io/2020/02/05/Hello-Echo/
http://Yihang-Li.github.io/2020/02/05/hello-world/
12.8 Parsing HTML using BeautifulSoup
BeautifulSoup tolerates highly flawed HTML and still lets you easily extract the data you need. See docs.
We will use urllib to read the page and then use BeautifulSoup to extract the href attributes from the anchor (a) tags.
1 | # Code: http://www.py4e.com/code3/urllinks.py |
The program prompts for a web address, then opens the web page, reads the data and passes the data to the BeautifulSoup parser, and then retrieves all of the anchor tags and prints out the href attribute for each tag.
You can use BeautifulSoup to pull out various parts of each tag as follows:
1 | # Code: http://www.py4e.com/code3/urllink2.py |
12.9 Something more
Scrape
When a program pretends to be a web browser and retrieves a web page, then looks at the web page content. Often programs are following the links in one page to find the next page so they can traverse a network of pages or a social network.Spider
The act of a web search engine retrieving a page and then all the pages linked from a page and so on until they have nearly all of the pages on the Internet which they use to build their search index.ASCII
American Standard Code for Information InterchangeEach character is represented by a number between 0 and 256 stored in 8 bits of memory(a byte of memory)
The ord() function tells us the numeric value of a simple ASCII character
(On the opposite, we can use chr())In Python3, all strings are unicode. When we read data from an external resource, we must decode it based on the character set so it is properly represented in Python3 as a string.
Summary
- The TCP/IP gives us pipes/sockets between applications
- We designed application protocols to make use of these pipes
- HyperText Transfer Protocol (HTTP) is a simple yet powerful proctocol
- Python has good support for sockets, HTTP, and HTML parsing
Chapter 13 Using Web Services
13.1 eXtensible Markup Language - XML
XML looks similar to HTML but more structured. See a sample below:
1 | <person> |
Often it is helpful to think of an XML document as a tree structure where there is a top tag person and other tags such as phone are drawn as children of their parent nodes.
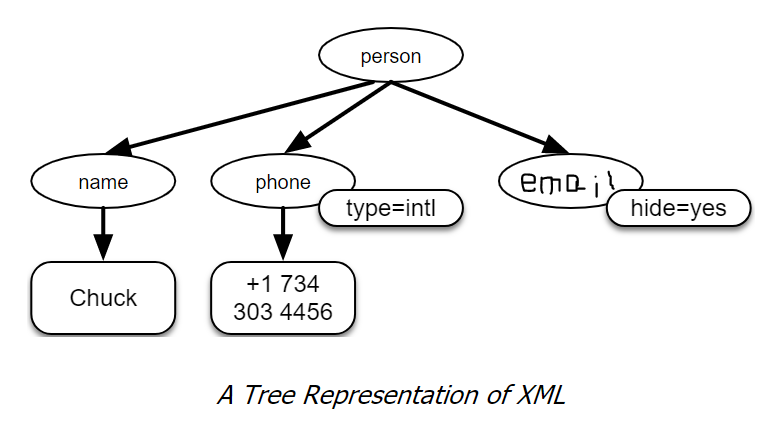
13.2 Parsing XML
1 | # Code: http://www.py4e.com/code3/xml1.py |
Output:
Name: Chuck
Attr: yes
Calling fromstring converts the string representation of the XML into a “tree” of XML nodes. When the XML is in a tree, we have a series of methods we can call to extract portions of data from the XML.
The find function searches through the XML tree and retrieves a node that matches the specified tag. Each node can have some text, some attributes (like hide), and some “child” nodes. Each node can be the top of a tree of nodes.
13.3 Looping through nodes
1 | # Code: http://www.py4e.com/code3/xml2.py |
Output:
User count: 2
Name Chuck
Id 001
Attribute 2
Name Brent
Id 009
Attribute 7
Note:
It is important to includes all parents level elements in the findall statement except for the top level element. Otherwise, Python will not find any desired nodes.
13.4 JavaScript Object Notation - JSON
The JSON format was inspired by the object and array format used in the JavaScript language. But since Python was invented before JavaScript, Python’s syntax for dictionaries and lists influenced the syntax of JSON. So the format of JSON is nearly identical to a combination of Python lists and dictionaries.
Here is a JSON encoding that is roughly equivalent to the simple XML from above:
1 | { |
In XML, we can add attributes like “intl” to the “phone” tag.
In JSON, we simply have key-value pairs. Also the XML “person” tag is gone, replaced by a set of outer curly braces.In general, JSON structures are simpler than XML because JSON has fewer capabilities than XML. But JSON has the advantage that it maps directly to some combination of dictionaries and lists. And since nearly all programming languages have something equivalent to Python’s dictionaries and lists, JSON is a very natural format to have two cooperating programs exchange data.
JSON is quickly becoming the format of choice for nearly all data exchange between applications because of its relative simplicity compared to XML.
13.5 Parsing JSON
We construct our JSON by nesting dictionaries (objects) and lists as needed. In this example, we represent a list of users where each user is a set of key-value pairs (i.e., a dictionary). So we have a list of dictionaries.
In the following program, we use the built-in json library to parse the JSON and read through the data. Compare this closely to the equivalent XML data and code above. The JSON has less detail, so we must know in advance that we are getting a list and that the list is of users and each user is a set of key-value pairs. The JSON is more succinct (an advantage) but also is less self-describing (a disadvantage).
1 | # Code: http://www.py4e.com/code3/json2.py |
Output:
User count: 2
Name Chuck
Id 001
Attribute 2
Name Chuck
Id 009
Attribute 7
- we get from json.loads() is a Python list which we traverse with a
forloop, and each item within that list is a Python dictionary. - In general, there is an industry trend away from XML and towards JSON for web services.
- But XML is more self-descriptive than JSON and so there are some applications where XML retains an advantage. For example, most word processors store documents internally using XML rather than JSON.
13.6 Application Programming Interfaces - API
API
A contract between applications that defines the patterns of interaction between two application componentsSOA
When we begin to build our programs where the functionality of our program includes access to services provided by other programs, we call the approach a Service-Oriented Architecture or SOA. (A non-SOA approach is where the application is a single standalone application which contains all of the code necessary to implement the application.)
We see many examples of SOA when we use the web. We can go to a single web site and book air travel, hotels, and automobiles all from a single site. The data for hotels is not stored on the airline computers. Instead, the airline computers contact the services on the hotel computers and retrieve the hotel data and present it to the user. When the user agrees to make a hotel reservation using the airline site, the airline site uses another web service on the hotel systems to actually make the reservation. And when it comes time to charge your credit card for the whole transaction, still other computers become involved in the process.
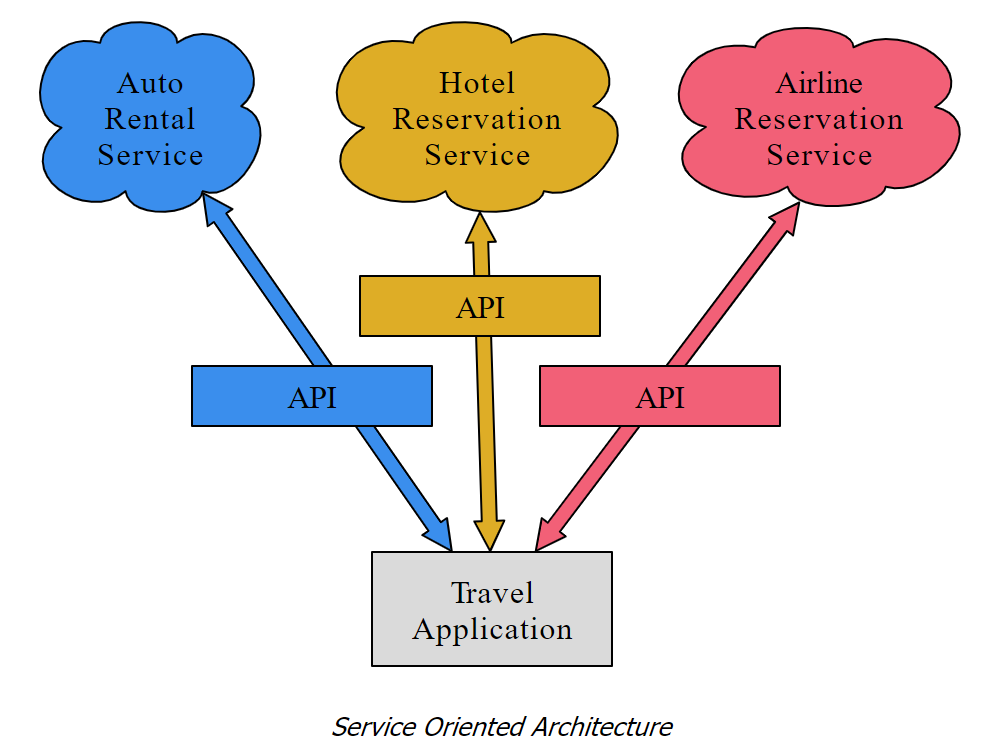
When an application makes a set of services in its API available over the web, we call these web services.
13.7 Security and API usage
It is quite common that you need an API key to make use of a vendor’s API.
The general idea is that they want to know who is using their services and how much each user is using.Sometimes once you get your API key, you simply include the key as part of POST data or perhaps as a parameter on the URL when calling the API.
Other times, the vendor wants increased assurance of the source of the requests and so they add expect you to send cryptographically signed messages using shared keys and secrets.A very common technology that is used to sign requests over the Internet is called OAuth.
13.8 Application
13.8.1 Google geocoding web service
When you are using a free API like Google’s geocoding API, you need to be respectful in your use of these resources. If too many people abuse the service, Google might drop or significantly curtail its free service.
Need API!
13.8.2 Twitter
As the Twitter API became increasingly valuable, Twitter went from an open and public API to an API that required the use of OAuth signatures on each API request.